
GJK Cat Informatika - Repozitář studijních materiálů
Vítejte na webu GJK Kočky, který slouží jako zdroj studijních materiálů jak od kantorů, tak od studentů. V postranní nabídce si můžete zvolit předmět a přesunout se na materiály daného předmětu. Stránky s učiteli a tagy seskupují obsah podle různých kritérií. Pokud byste rádi přidali nějaké materiály na tento web, podívejte se na https://gjk.cat.
Vytváření materiálů na platformě gjk.cat vyžaduje znalost Git(hub)u a formátu Markdown. Pokud je neznáte, navštivte https://gjk.cat.
Kontakt
Tuto wiki spravuje Lukáš Hozda. Pro více kontaktních informací navštivte mojí kartu učitele.
Předměty
| Název | Unixové operační systémy |
|---|---|
| Zodpovědná osoba | Emil Miler |
| Popis | V tomto předmětu se probírají unixové operační systémy a pokročilejší informatika |
Unixové operační systémy
Cílem předmětu je studenty seznámit s rodinou unixových operačních systémů a naučit je, jak s nimi pracovat. Naučí se ovládat shell, psát vlastní skripty, spravovat serverové aplikace. Ve výsledku budou umět Linuxové systémy použít nejen jako náhradu za proprietární operační systémy. Předmět se zaměřuje i na obecná témata z oblasti hardwaru, počítačových věd, sítí a bezpečnosti.
Seznam materiálů
- Bezpečnost
- Huffmanovo kódování
- Imperativní programování
- Kódování znaků
- Minimalizace
- Paměti
- Programovací jazyk C
- Prvo v IT
- Reprezentace čísel v paměti
- Shell
- Složitosti algoritmu
- Sítě
- Unix
- Verzovací systém git
- Verzovací systémy
| Název | Bezpečnost |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Bezpešnost
Bezpečnost je velmi široký pojem, do kterého můžeme zahrnout obrovské množství věcí. Nás zajímá hlavně bezpečnost chování na síti, bezpečnost aplikací, ukládání dat a bezpečná práce s daty.
Ukládání dat
Měl jsem akamarádku, kterou nenapadlo nic lepšího, než ukládat svou bakaláčkou práci jen na jednu flešku. Když na práci chtěla pracovat, připojila flešku a pracovala se soubory přímo na ní. Jednoho dne se fleška rozhodla přestat fungovat.
Data se z FLASH pamětí dostávají velice obtížně a stojí to neskutečné množství peněz. Z plotnových disků se ztracená data zachraňují snáz, ošem lepší je ztrátě dat úplně předcházet.
Tagy
| Název | Huffmanovo kódování |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Huffmanovo kódování
Jde o kompresní algoritmus, který využívá strom pro zakódování vstupu. Funguje na tom principu, že nejčastěji opakující-se znaky mají nejmenší bitový popis a nejméně časté znaky mají na svůj popis nejvíce bitů. My se věnujeme jen statickému Huffmanovo kódování.
Vlastnosti:
- Bezztrátový
- Asymetrický
- Dvou-průchodový
V praxi se využívá překvapivě často, například jako část komprese ve formátu JPEG při redukci opakujících-se pixelů.
Postup zakódování
Pro příklad budeme mít vstup řetězec ABRAKADABRA.
Seřazení znaků
Prvním krokem je důležité vyfiltrovat unikátní znaky, což jsou v tomto případě znaky A B R K D. Ke každému znaku zároveň připíšeme číslo označující počet výskytů znaku v řetězci.
Dále vypíšeme znaky seřazené sestupně (od nejvíce výskytů po nejméně výskytů). Seřazené znaky budou tvořit spodní část stromu.
 {width=50%}
{width=50%}
Vytvoření stromu
K vytvoření stromu je třeba spojit dva objekty s nejmenším počtem výskytů a jejich počet sečíst. Pokud jsou více než dva objekty se stejným číslem, můžeme si libovolně vybrat.
 {width=50%}
{width=50%}
Každá objekt může mít pouze dva potomky. Tím je strom kompletní.
Zakódování vstupu
Každou větev stromu si označíme, například levou větev jako 1 a pravou větev jako 0.
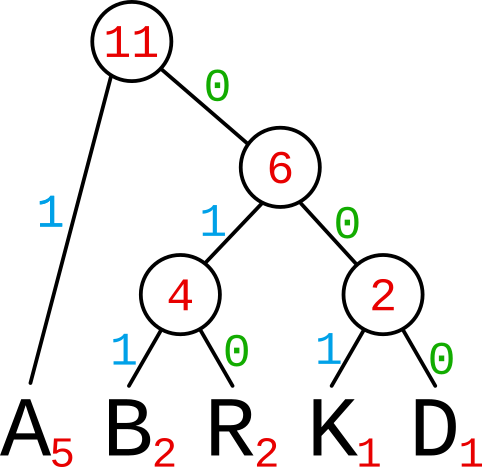 {width=50%}
{width=50%}
Zakódování pak probíhá jen tak, že zmapuji cestu ke znaku.
 {width=50%}
{width=50%}
Znaky budou mít tedy tyto kódy:
A 1
B 011
R 010
K 001
D 000
Zakódování řetězce už je jen o popsání správných jedniček a nul podle vstupu.
ABRAKADABRA = 10110101001100010110101
Postup dekódování
Dekódování funguje tak, že podle zakódovaného řetězce postupujeme hlouběji do stromu,dokud nenarazíme na znak.
1 011 010 1 001 1 000 1 011 010 1
A B R A K A D A B R A
Huffmanovo kódování je navrženo tak, že se při čtení zakódovaného řetězce nedostaneme do konfliktu a vždy přistaneme na správném znaku.
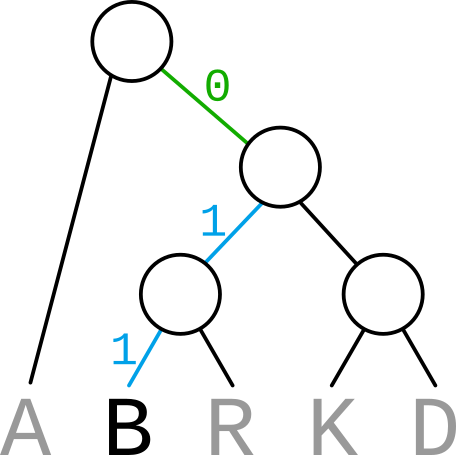
Zakódování a rekonstrukce stromu
Když pošleme zakódovanou zprávu, příjemce jí bez stromu nedokáže dekódovat. Proto je nutné poslat i samotný strom.
Strom lze zakódovat tak, že ho celý projdeme. Každou cestu hlouběji do stromu označíme jako 1 a návrat zpět jako 0.
 {width=50%}
{width=50%}
Zakódovaný strom bude tedy 1011101001101000. Spolu s ním musíme poslat i znaky ve stromu, tedy ABRKD.
Jeho rekonstrukce probíhá opačně, tj. podle zakódovaného řetězce stromu kreslíme větvě - při 1 jdeme do hloubky a při 0 se vracíme po větvi zpět.
Tagy
| Název | Imperativní programování |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Imperativní paradigma
Říkám počítači, jak chci něco provést. Popisuji tedy postup.
Příklady jazyků:
- C
- Basic
- BrainFuck
- Rust
- Go
- Python
Sruktura
Proměnná
Označení části paměti, ve které můžeme uložit vlastní data.
Podmínky
Cykly
Procedura & funkce
Datové typy
Integer
Označení int. Maximální 2^32. Signed int má rozsah <-2^31,2^31-1>.
Float & Double
Desetinné čílo. Double má větší rozsah než float.
Char
ANSII znaky
Pole
Unsigned
Tagy
| Název | Kódování znaků |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Kódování znaků
Dříve existovaly teletypery/teleprintery - po síti byl poslán znak a tele-type ho natiskl na papír.
S příchodem počítačů vznikala spousta různých standardů. Například v Japonsku vznikly 4 různé standardy mezi sebou nekompatibilní. To při odeslání textu z jednoho počítače na druhý produkovalo jen rozházený text. V japonštině pro označení takové situace dokonce vzniklo slovo mojibake.
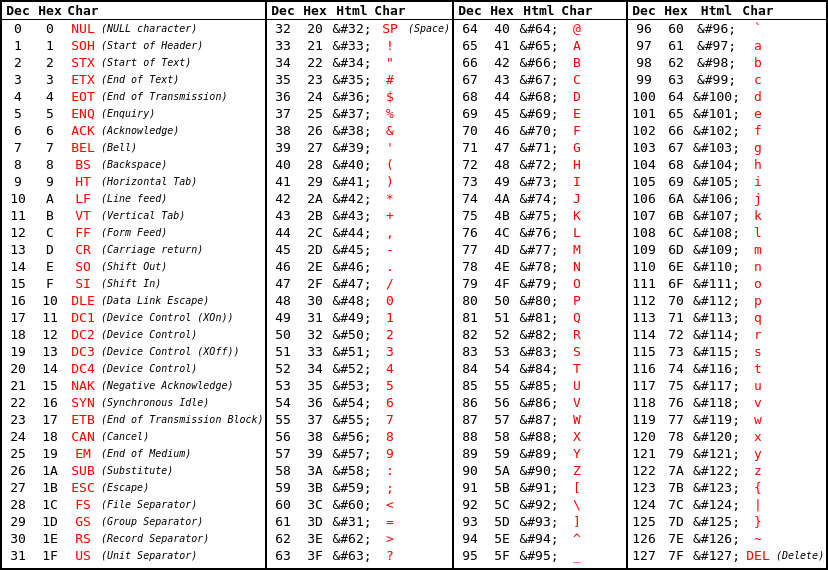
ASCII
American Standard Code for Information Interchange. Standard pro kódování znaků vytvořený primárně pro teleprintery. Znaky jsou kódovány v sedmi bitech. Počet možných znaků je tedy 128. Znaky mají přesně definované číslo, ke kterému patří.
Znak A je v ASCII definován jako 65 1000001 a znak a jako 97 1100001. Lze tak jednoduše určit zakódované znaky okem přímo z binární soustavy.
 {width=100%}
{width=100%}
Z ASCII později vycházely standardy pro specifické jazyky, které mezi sebou nejsou kompatibilní.
UTF-8
Standard prvotně načrtnutý na ubrousku v jídelně (Ken Thompson a Rob Pike). Unicode má seznam 277021 znaků ve verzi (11.0 červen 2018). UTF-8 může kódovat až 1112064 znaků.
Příklad: Kdybychom chtěli zakódovat znak
Apřímo do např. 32b, dostali bychom00000000000000000000000001000001. To nám navýší velikost souboru 4.5 krát. Staré počítače zároveň vyhodnotí nulový byte00000000jako konec řetězce.
Pokud v UTF-8 chceme zakódovat znak, který patří do ASCII tabulky (jde zakovat v sedmi bitech), zakódujeme ho stejně a na začátek přidáme nulu, tedy A 65 01000001.
Další znaky se kódují pomocí hlaviček v bytech.
| volné bity | byte 0 | byte 1 | byte 2 | byte 3 |
|---|---|---|---|---|
| 11 | 110xxxxx | 10xxxxxx | ||
| 16 | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 21 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
110 udává, kolik hlaviček v řetězci je. V dalším bajtu je hlavička 10, která označuje začátek bloku. Prázdná místa x jsou použita jako datová. Pomocí hlaviček získáme strukturu dat a jejich odstraněním z řetězce bitů získáme samotná data.
UTF-8|Obsah bloků bez hlaviček|Číslo v base10 -|-|-|- 1101000110111000|10001111000|1114 111010011010111010011011|1001101110011011|39835
- Nenastane situace, kdy bude osm
0za sebou - Neplýtvá se místem
Tagy
| Název | Minimalizace |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Minimalizace
V tomto příkladu si vytvoříme driver jednoho segmentu sedmi-segmentového displeje a provedeme jeho minimalizaci.
Vytvoření driveru
Vybereme se jeden segment z displeje, pro který navrhneme driver.
 {height=100px}
{height=100px}
Pro popis hodnot od 0 do 9 potřebujeme 4 bity - potřebujeme tedy 4 vstupy. Jako první je třeba vypsat stavy, při kterých bude segment svítit. Vypíšeme si tedy 4-bitová binární čísla s hodnotami 0 až 9.
x A B C D
0 0 0 0 0
1 0 0 0 1
2 0 0 1 0
3 0 0 1 1
4 0 1 0 0
5 0 1 0 1
6 0 1 1 0
7 0 1 1 1
8 1 0 0 0
9 1 0 0 1
A, B, C a D jsou naše 4 vstupy a x je pouze hodnota v desítkové soustavě. Nyní musíme přidat výstupní bit Q, který nám definuje, při jaké hodnotě bude segment rozsvícen. U čísla 0 svítit bude, ale například u čísla 5 ne.
x A B C D Q
0 0 0 0 0 1
1 0 0 0 1 1
2 0 0 1 0 1
3 0 0 1 1 1
4 0 1 0 0 1
5 0 1 0 1 0
6 0 1 1 0 0
7 0 1 1 1 1
8 1 0 0 0 1
9 1 0 0 1 1
Sice nám zbývají další nevyužité hodnoty (10, 11, 12 atd.), ale u těch je nám nezáleží na jejich stavu. To se nám hodí později při minimalizaci.
Nyní si vypíšeme funkci, která popisuje všechny stavy, při kterých bude segment svítit. Například hned u stavu s hodnotou 1 svítit bude, proto popíšeme stavy vstupů jako $\bar{A}\bar{B}\bar{C}D$. Vstupy s hodnotou 0 označíme čarou nad písmenem, což je NOT. Znaménko $$ samozřejmě označuje AND a znaménko $+$ značí OR.
$$ f(x) = \ \bar{A}\bar{B}\bar{C}\bar{D} + \ \bar{A}\bar{B}\bar{C}D + \ \bar{A}\bar{B}C\bar{D} + \ \bar{A}\bar{B}CD + \ \bar{A}B\bar{C}\bar{D} + \ \bar{A}B\bar{C}D + \ \bar{A}BC\bar{D} + \\bar{A}BCD + \ A*\bar{B}\bar{C}\bar{D} + \ A*\bar{B}*\bar{C}*D $$
A máme hotový vzorec pro implementaci jednoho segmentu. Pokud bychom ale chtěli tuto věc implementovat, potřebovali bychom 25 NOTů, 30 ANDů a 9 ORů, to je celých 64 součástek!!!? Proto je dobré provést minimalizaci.
Minimalizace
Minimalizace nám pomůže zjednodušit náš vzorec pro implementaci a v reálném světě nám ušetří spousty peněz za součástky.
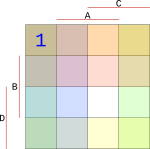
V našem případě využijeme Karnaughovu mapu o velikosti $4*4$.
 {width=300px}
{width=300px}
Do mapy doplníme všechny stavy při hodnotách 0 až 9 z naší první tabulky z výstupy Q. Mapa se vyplňuje tak, že musíme najít jeden společný průnik všech vstupů. Začneme vstupem A. Ten má na hodnotu 0, vybereme tedy bloky v mapě, pro které platí, že A je 0.
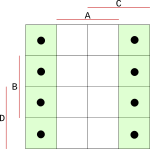 {width=150px}
{width=150px}
 {width=150px}
{width=150px}
 {width=150px}
{width=150px}
 {width=150px}
{width=150px}
\newpage
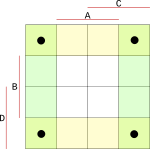
Do bloku, na který jsme narazili sečtením všech průniků, zapíšeme hodnotu zda segment svítí nebo nesvítí. Protože jsme hledali blok pro desítkovou hodnotu 0, při které bude segment svítit, dáme do mapy hodnotu 1 (bude svítit). Stejným postupem vyplníme celou tabulku pro zbylé hodnoty 1 až 9.
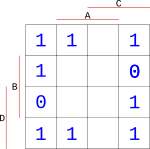 {width=150px}
{width=150px}
Pro minimalizaci musíme seskupit všechny hodnoty 1 do skupin nejlépe po čtyřech. Čím větší bloky, tím větší zjednodušení výsledku.
Pro Karnaughovu mapu platí, že hodnoty lze seskupovat i přes hrany, či přes rohy. Detaily o tom proč a jak toto funguje jsou popsány například na wikipedii.
Další specialita mapy je ta, že nevyplněné bloky si můžeme doplnit podle potřeby. Vzpomeňte si na začátek dokumentu, kde nám zbylo několik nevyužitých hodnot pro čísla 11, 12 atd. U těch je nám jedno, v jakém stavu budou, a proto si je do mapy můžeme doplnit podle sebe a tím si uměle vytvořit lepší bloky pro minimalizaci.
První blok se nám nabízí například vlevo nahoře, kde si můžeme doplnit jedničku a vytvořit blok $2*2$.
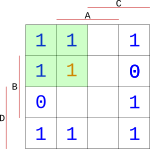 {width=150px}
{width=150px}
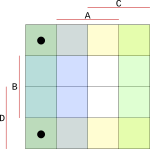
Dále můžeme využít to, že bloky lze vytvářet i přes rohy. V každém rohu se nachází 1, tak je dáme do dalšího bloku.
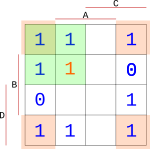 {width=150px}
{width=150px}
\newpage
Tímto způsobem dotvoříme zbytek bloků, dokud nebudou v blocích všechny námi vypsané (modré) jedničky.
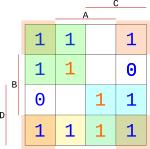 {width=150px}
{width=150px}
Všechny bloky teď popíšeme do vzorce. Protože bloky jsou o velikosti $2*2$, stačí nám na popis každého bloku pouze dva vstupy.
$$ f(x) = \bar{C}\bar{D} + \bar{A}\bar{B} + DC + D\bar{B} $$
To dám dohromady dává pouze 12 součástek. Základní minimalizace je kompletní.
Tagy
| Název | Paměti |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Paměti ROM
PROM
Programovatelná paměť, do které lze zapsat jen jednou.
EPROM
Programovatelná paměť, kterou lze smazat UV zářením.
EEPROM
Programovatelná paměť, kterou lze smazat elektrickým nábojem.
Paměti RAM
- Lze přiepisovat bloky po bitech
- To umožňuje tzv. bit select tranzistor
- Je třeba mít více tranzistorů na buňku
DRAM
Dynamic RAM
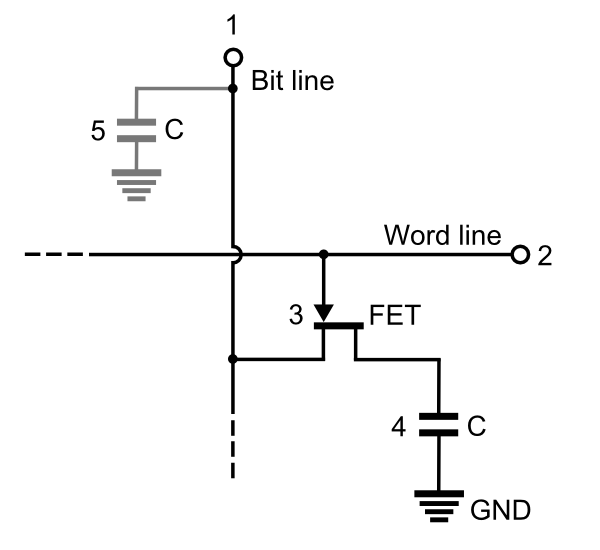
- Je nutné ho neustále dobíjet
- Obsahuje pouze jeden FET
- Jednoduché na výrobu
- Levné
- Používá se v operačních pamětech
SRAM
Static RAM
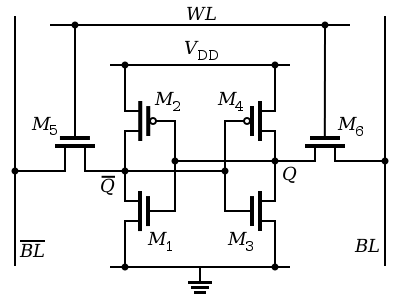
- Obsahuje invertory
- Není třeba neustále refreshovat
- Rychlé operace
- Postaven z šesti tranzistorů
- Zabírá větší plochu
- Je dražší na výrobu
- Používá se v CACHE pamětech
Paměti FLASH
-
Nevolatilní paměť
-
Do buňky lze provést jen omezený počet zápisů
-
Mažou se celé bloky (i během přepisu jednoho bitu)
- blok paměti se smaže (logické 1)
- relevantní bity se zapíší (pouze logické 0)
-
Zápis je rychlý
-
Mazání pro přepis je pomalé
- TRIM u SSD
Běžné velikosti pamětí:
| EEPROM | NOR | NAND |
|---|---|---|
| 64K - 512K | 512K - 128M | 128M - nGB |
Ovšem tyto velikoti se odvíjí od ceny. Lze vytvořit jakoukoliv velikost paměti.
Floating-gate tranzistor
Varianta MOSFET s přidanou bránou, která dokáže uchovat záporný elektrický náboj (logická 1), nebo žádný náboj (logická 0).
----------------+
|
Gate
| <- dielektrikum
+---Floating gate---+
| | <- dielektrikum
--- Source Drain --- GND
U jiných druhů (MLC, TLC, QLC) se jen přidají stavy náboje.
NAND
- Paměť postavená na NotAND hradlech
- Počet zápisů je mezi 500 - 100000.
- Sekvenční přístup k datům
Druhy buňek:
| SLC | MLC | TLC | QLC |
|---|---|---|---|
| 1b | 2b | 3b | 4b |
NOR
- Náhodný nebo sekvenční přístup k datům
- Použití u BIOS chipů, ovládacích IC u procesorů atd.
- Výhodou je vyšší životnost (nemusí ze přepisovat buňky v sekvenci)
Magnetické paměti
HDD
- Elektro-mechanické zařízení
- Data se ukládají maggnetizovaním sektorů na plotně
- Plotna je rozdělena na stopy a sektory od středu disku.
Hybridní HDD obsajují i paměť FLASH.
Magnetická Páska
Disketa
Disk rozdělen na sektory, stejně jako HDD.
Optické paměti
- Data jsou na disku od středu směrem ke kraji
- Spirálový zápis
- Díra 0, plocha 1
- Laser se odráží (na ploše) do fotoelektického senzoru
- Objem uložitelných dat závisí na velikosti pitů a landů
| Technologie | Objem dat | Velikost díry | Průměr paprsku | Vlnová délka ($\lambda$) |
|---|---|---|---|---|
| CD | 0.7 GB | 800x600 nm | 1.6 um | 780 nm |
| DVD | 4.7 GB | 400x320 nm | 1.1 um | 650 nm |
| Blu-ray | 25 GB | 150x130 nm | .48 um | 405 nm |
DVD+R vs. DVD-R
+ a - označují metody zjištění relativní polohy laseru (čtecí hlavy). Metoda - zjišťuje polohu pomocí převytvořených děr (prepits). Metoda + měří kmitání disku a jeho úroveň jeho vychýlení -- čím větší vychýlení, tím dále od středu se hlava nachází.
RW
Fungují na principu fázového posunu světelného spektra. Zahřátím dojde k roztavení materiálu, který nepropouští světlo. Paprsek se pak neodrazí od reflektivní vrstvy do senzoru.
MiniDisc
- Magneto-optické disky
- Magnet na disk zapisuje, laser čte
- Při zápisu laser nahřeje disk na 200° C
Další formáty
- LaserDisc
- MiniCD
- MiniDVD
- UMD
- MiniDisc
Tagy
| Název | Prvo v IT |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Proprietární software
EULA
Svobodný software
Čtyří základní svobody:
- 0: Používat program jakkoliv a za jakýmkoliv účelem.
- 1: Studovat zdrojový kód a provádět na něm úpravy.
- 2: Distribuovat program komukoliv a jakýmkmoliv způsobem.
- 3: Distribuovat vlastní modifikovanou verzi programu.
GPL
GPLv2
GPLv3
MIT
BSD
Non-Disclosure Agreenment
Smlouva o mlčenlivosti a zachování informací. Uzavřeno mezi dvěma a více subjekty, např. zákaz šíření zdrojového kódu apod.
NDA musí obsahovat:
- Definici toho, co přesně spadá pod NDA.
- Dobu platnosti NDA.
- Podmínky v případě porušení.
Service-Level Agreenment
Smlouva mezi uživatelem a poskytovatelem služby. SLA poposuje, co poskytovatel zprostředkuje uživateli, za jakých podmínek, cenu apod.
Open-Source vs Free Software
- Svobodný software splňuje 4 základní svobody
- OpenSource navazuje na svobodný software s cílem zalíbit se korporacím
- OpenSource je jen o sdílení zdrojového kódu, ovšem ne nutně bez ostatních svobod
Creative Commons
Licenční prvky:
- Právo dílo šířit
- Právo dílo upravovat
- Uvedení autora
- Zachování licence
- Nevyužívání díla komečně
- Nezahahovat do díla
Copyright v Česku
Tagy
| Název | Programovací jazyk C |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Základní struktura
int main(void){
return 0;
}
Pro práci se standardním vstupem/výstupem potřebujeme importovat knihovnu stdio.h. Chceme-li tedy vypisovat něco na výstup, potřebujeme knihovnu.
#include <stdio.h>
int main(void){
printf("Hello World!");
return 0;
}
Proměnné
#include <stdio.h>
int main(void){
int a = 5;
int b = 7;
int c = a + b;
printf("%d+%d=%d\n",a,b,c);
return 0;
}
Vstup od uživatele
#include <stdio.h>
int main(void){
int a, b, c;
printf("Zadej dve cisla...\n");
scanf("%d %d", &a, &b);
c = a + b;
printf("%d+%d=%d\n",a,b,c);
return 0;
}
Podmínky
Ověření, zda tři velikosti tvoří pravoúhlý trojúhelník.
#include <stdio.h>
int main(void){
int a, b, c;
printf("Zadej tri rozmery sten trojuhelniku...\n")
scanf("%d %d %d", &a, &b, &c);
// zjistit ktere cislo je nejvetsi
if(c*c == a*a + b*b){ // Pythagorova veta
printf("trojuhelnik je pravouhly\n");
}else{
printf("trojuhelnik neni pravouhly\n");
}
printf("%d+%d=%d\n",a,b,c);
return 0;
}
Cykly
funkce & procedury
Pointer
Tagy
| Název | Reprezentace čísel v paměti |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Reprezentace čísel v paměti
Binární soustava
Počítače vidí rozumí jen binárním stavům, které reprezentujeme jako 1 a 0.
Hexadecimální soustava
894 -> 37E
894 /16 | 55.875 | r14 55 /16 | 3.4375 | ...
37E = E * 16^0 +7 * 16^1 +3 * 16^2
14 * 1 +7 * 16 +3 * 256 = 894
479 -> 1DF
Integer
Unsigned int
- scitani mocnin dvou
- 8 bitu (char) -> 256 hodnot
Signed int
Číslo se znaménkem. Reprezentuje se tak, že první bit definuje znaménko, kde 1 je mínus a 0 je plus. Efektivní rozsah je -128 až 127.
Záporné číslo je znározněné doplňkovým kódem. Znamená to, že přičítáme směrem k nule od -128. Máme-li binární signed int 10000001, nejde o číslo -1, ale o -127. Přičetli jsme totiž jedničku (0000001) k -128.
Doplňkový kód lze vypočítat jednoduše. Chceme-li získat záporné číslo -25, stačí nám 25 zkonvertovat do dvojkové soustavy (7 bitů) - což je 0011001 - a invertujeme všechny bity na 1100110. Poté přidáme jako první bit znaménko, tj. 1 a dostaneme číslo -25.
-13 je 11110011, 13 je 0001101. Dopocitava se k nule, tj. 1001101 je -128 + 13 = -115. muzem invertovat bity a vyjde to.
Float
V desétkové soustavě zapisujeme desetinné číslo ve formátu 1000 100 10 1 . 1/10 1/100 1/1000.
Číslo, které není rekurzivní v jedné soustavě, může být rekurzivní v jiné soustavě. Zlomek $\frac{1}{3}$ zapíšeme v desítkové soustavě jako $0.\overline{3333333}$. Stejně tak číslo $0.1$ zapíšeme v binární soustavě jako $0.0001100\overline{1100110011}$. Počítače nerozumí rekurzi, což znamená, že při práci s destinými čísli přicházíme o přesnost.
$0.1 + 0.2 = 0.300000...000001$
$\frac{1}{3} + \frac{1}{3} + \frac{1}{3} = 0.3\overlive{333333} + 0.3\overline{333333} + 0.3\overline{333333} = 1$
u vypoctu zbytku (z floatu na binarni) nasobime zakladem (2).
7/10 | 1
4/10 | 0
8/10 | 1
6/10 | 1
2/10 | 0
4/10 | 0 |
8/10 | 1 |
6/10 | 1 |
...
- v pameti jsou cisla s plovouci nebo pevnou desetinno ucarkou
- u starych jsou s pevnou, tj. presne dany pocet cifer pred a za carkou
- omezeny rozsah cisel
- s plovouci carkou je znazornene, kde se carka nachazi
- maji kladnou i zapornou nulu lol
- dane u IEEE-754
- neperiodicke cislo v jedne soustave muze byt periodicke v druhe
0.1 + 0.2 = 0.30000000000004
Tagy
| Název | Sítě |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Síťové prvky
Client
Hub
Switch
Router
Gateway
Adresy
- IP adresa
- MAC adresa
TCP/IP
Jde o síťovou architekturu, která vychází ze síťového modelu ISO/OSI. Nejdříve byly navrhnuty protokoly, později až architektura přímo pro počítačové sítě. Funguje nespolehlivě a nespojovaně na principech Best Effort a přepojování paketů.
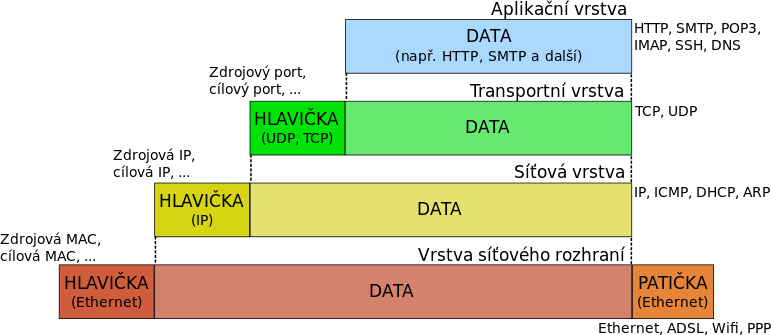
Vrstva síťového rozhraní
- Sloučené vrstvy L1 a L2 z ISO/OSI
- Pracuje s Ethernet rámci
- Kódování
- Samotná binární data
Síťová vrstva
- IP adresy
- Směrování
- ARP, ICMP, ...
- Rozdělení dat na pakety / datagramy
- Uspořádání příchozích paketů / datagramů do původní podoby
Transportní vrstva
- TCP / UDP
- Stará se o integritu dat apod.
Aplikační vrstva
- Implementace protokolů (https, sftp, ssh, ntp, ...)
- Samotné aplikace komunikují s aplikační vstrvou pomocí portů (http 80, ssh 22, ...)
Verze IP
IPv4
Numerické adresy pro síťovou vrstvu ve formátu čtyř čísel v rozsahu 0-255 oddělených tečkou: 192.168.1.1. Adresy jsou popsány 32 bity. Počet možných IPv4 adres je tedy $2^{32} = 4.29 * 10^{9}$.
IPv6
Adresy jsou popsány 128 bity, tj. $2^{128} = 3.4 * 10^{38}$. Adresy IPv6 jsou popsány v osmi blocích čtyř hexadecimálních znaků oddělených dvojtečkou: fd2f:77df:6fe6:0:5da8:f2da:1058:4a4b.
DHCP - Dynamic Host Configuration Protocol
ARP - Address Resolution Protocol
DNS - Domain Name System
Síťové technologie
IEEE 802.3 - Ethernet
10BASE5/2
10BASE-T
100BASE-TX
1000BASE-T
IEEE 802.11 - WiFi
Tagy
| Název | Shell |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Shell je rozhraní pro uživatele umožňující uživatelům spouštět a ovládat programy, tj. Interpretuje uživatelem zadané příkazy systému.
Shellů existuje celá řada. Nejběžněji používaným shellem je Bash.
Základní programy
Práce se soubory a složkami
- ls — vypsat obsah složky
- cd — přepnou se do složky
- pwd — vypsat adresu aktivní složky
- cat — vypsat obsah souboru/ů
- touch — vytvořit prázdný soubor
- mkdir — vytvořit prázdnou složku
- rm — odstranit soubor/složku
- cp — zkopírovat soubor/složku
- mv — přesunout/přejmenovat soubor/složku
Proudové editory
- grep — vyhledá všechny řádky obsahující daný obsah
- sed — najít a nahradit
- awk — vypisuje dané sloupce
Proudy
| Znak | Funkce |
|---|---|
| | | Přesměrování výstupu na vstup jiného programu |
| > | Přepsat soubor |
| >> | Připsat na konec souboru |
Aliasy
Alias je uživatelem definovaná zkratka. Pomocí aliasu lze na vybrané klíčové slovo nastavit složitý příkaz, který lze poté vyvolat samotným Klíčovým slovem.
Alias lze nastavit přímo v terminálu: alias testalias="echo 'i love pizza'". Po definování tohoto aliasu a napsáním klíčového slova testalias se spustí definovaný příkaz echo 'i love pizza'.
$ alias testalias="echo 'i love pizza'"
$ testalias
i love pizza
Příkladem aliasu může být namapování příkazu cal -m na klíčové slovo cal. To nám umožní automaticky vyvolávat kalendář s prvním dnem nastaveným na pondělí bez toho, aniž bychom museli přepínač -m definovat pokaždé manuálně.
Persistentní aliasy
Po uzavření okna terminálu se nastavené aliasy resetují. Pro jejich uchování je třeba aliasy definovat v konfiguračním souboru shellu, v našem případě tedy v souboru .basahrc v našem domovském adresáři.
V konfiguračním souboru stačí na nové řádky aliasy definovat stejně, jako když je definujeme přímo v terminálu.
Tagy
| Název | Složitosti algoritmu |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Složitosti algoritmu
Algoritmus je popis nějakého postupu.
- délka kódu
- počet provedených instrukcí
- doba běhu programu
- počet cyklů
| funkce | $N = 10$ | $N = 100$ | $N = 1000$ | $N = 10000$ |
|---|---|---|---|---|
| $log_2 N$ | 1 | 2 | 3 | 4 |
| $N$ | 10 | 100 | 1000 | 10000 |
| $L log_2 N$ | 10 | 200 | 3000 | 40000 |
| $N^2$ | 100 | 10000 | $10^6$ | $10^8$ |
| $2^n$ | 1024 | $10^31$ | $10^310$ | $10^3100$ |
for(i = 0; i < n; i++){
printf("*");
}
slozitost je $3n+1$, tj. $O(n)$.
- 1 prirazeni
- n porovnani
- n souctu
- n print
for(i = 0; i < n; i++){
for(j = 0; h < n; j++>){
printf("*");
}
}
slozitost je $n*(3n+1)+1+n = 3n^2+3n+1$, tj. $n^2$.
- 1 prirazeni
- n i++
- n prirazeni
- n^2 j++
for(i = 0; i < n; i++){
for(j = 0; j < i; j++){
printf("*");
}
}
$0+1+2+3+...+n = \frac{(n^2+n)}{2} = \frac{1}{2}n^2 + \frac{1}{2}n^2 = O(n)^2$
while(n >= 1){
printf("*");
n = n/2;
}
Bubble sort ma slozitorst $O(n^2)$
Tagy
| Název | Unix |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Základní prvky *nixového systému (POSIX)
- Vše je soubor
- Program dělá jednu věc a dělá jí dobře
- Výstup jednoho programu může býti vstupem jiného programu
- Programy umí zpracovat textové proudy
Souborový systém
Souborový systém unixového systému se od systému Windows liší tím, že je vše umístěno pod hlavním tzv. kořenovým adresářem /. Příklad souborové struktury:
/
bin
dev
etc
home
adam
documents
videos
petr
music
Absolutní a relativní cesty
Popis cesty v unixovém systému se zapisuje pomocí názvů složek/souborů a znaku /. Cesta začínající tímto znakem definuje to, že cesta začíná v kořenovém adresáři a je tedy absolutní, například /home/user/documents/school. Relativní popis cesty je kterýkoliv jiný popis.
Relativní cesta může začínat jen názvem složky, nebo jedním ze speciálních znaků:
| Znak | Definice |
|---|---|
| . | Aktuální složka (working directory) |
| .. | Rodičovská složka (složka nadřazená aktuálnímu adresáři) |
| ~ | Domovská složka přihlášeného uživatele (/home/$USER) |
Relativní cestou je například ../documents/school, nebo ~/documents/school atd.
Tagy
| Název | Verzovací systémy |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Verzovací systémy
Verzovací systémy slouží k organizaci sdílené práce na souborech. Tyto systémy se označují jako VCS (Version Control System).
Před nástupem VCS se soubory sdílely různými způsoby, např. přenášením na fyzických médiích, či po síti. Nebylo ovšem spolehlivě zjistitelné, která verze souboru je aktuální/správná.
Pokud se na úpravách jednoho souboru, například programu, chtělo podílet několik uživatelů, mohli mít všichni v jednu chvíli přístup k souboru na serveru. Ovšem pokud soubor upravovovali dva uživatelé ve stejnou chvíli, změny posledního uživatele, který zapsal změny, přepsaly všechny uložené změny předchozího uživatele.
Centralizované systémy
Tyto systémy se vyznačují tím, že soubory i jejich historie jsou umístěny na jednom zařízení - serveru. Ze serveru si uživatelé stahují vybrané verze souborů a pracují na nich.
Zamykání souboru
Pokud jeden uživatel otevře soubor pro editaci, ostatním uživatelům je umožněno soubor pouze číst. Tento systém zapříčiní vzniku konfliktu při slučování různých verzí.
Nevýhodou je, že zápis může v jednu chvíli provádět pouze jeden uživatel. To nemusí být v produkci účinné.
CVS
Concurrent Version System, ve zkratce CVS, je jedním z prvních rozšířených distribuovaných systémů. Byl vyvíjen jako součást projektu GNU a dodnes se v některých projektech používá. Je to ovšem již archaický systém bez dalšího zásadního vývoje.
Subversion
Subversion, nebo-li SVN, je systém, který měl za cíl nahradit CVS a opravit jeho nedostatky. Oproti CVS umí lépe řešit konflikty a manipulace se soubory, uchovávat v repozitářích i jiná data kromě textových souborů a větvit repozitář.
Stavy repozitáře se vypočítávají na základe předchozích změn. Výhodou toho je, že se šetří úložiště, ovšem výpočet rozsáhlého projektu může být velmi náročný. Podle zásad nepatří velké binární soubory do repozitáře, čímž se výhoda s využitým místem stává nepodstatnou.
Distribuované systémy
U distribuovaných systémů jsou zdrojové soubory - včetně celé historie repozitáře - uloženy na zařízeních všech uživatelů, kteří s repozitářem pracují. Změny se poté synchronizují do hlavního repozitáře na serveru.
Mercurial
Mercurial, často zmiňovaný zkratkou hg je distribuovaný verzovací systém. Vznikl přibližně ve stejné době jako git, liší se jednak tím, že je monolitický (jedna binárka) a orientací na přátelskost použití. Několik uživatelů popisuje Mercurial jako "DropBox pro programátory".
Zajímavé je, že že někteří poskytovatelé se Mercurialu zbavují a zachovávají pouze git, například Bit Bucket.
Git
V současnosti nejrozšířenější verzovací systém. který byl napsán Linusem Torvaldsem, autorem kernelu Linux. Právě pro vývoj Linuxu byl git napsán. Podobně jako Mercurial se jedná o distribuované VCS, ovšem Git je spousta malých programů, oproti monolitickému Mercurialu.
Git umí velmi dobře procházet a manipulovat s historií repozitáře, je velmi flexibilní a poměrně jednoduše rozšiřitelný přes shellové skripty.
Na rozdíl od SVN uchovává git kopie každé revize, respektive změněných souborů, a nevypočítává jejich stavy na základě změn.
Tagy
| Název | Verzovací systém git |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Unixové operační systémy |
Git
Git je distribuovaný verzovací systém.
Získání souborů a kontrola stavu
clone
Slouží k vytvoření lokální kopie vzdáleného repozitáře.
git clone <remote address>
pull
Synchronizuje lokální verzi repozitáře se vzdáleným repozitářem, tj. stáhne všechny změny.
git pull
status
Vypíše všechny neuložené změny v lokálním repozitáři (které nejsou v commitu).
git status
log
Vypíše poslední provedené commity, jejich popis, ID a další informace.
git log
Nahrání změn

add
Připraví vybrané soubory ke commitu. Dokud se neprovede commit, lze soubory přidávat a odstraňovat.
git add <file>
commit
V podstatě "zabalí" všechny připravené soubory a vytvoří nový stav, ke kterému se v budoucnu lze vrátit. Změny provedené v commitu standardně nelze měnit.
Příkaz pro commit otevře editor, ve kterém se na první řádek napíše stručný popis změn s maximálním počtem 72 znaků. Na další řádky lze změny popsat do detailu, ovšem řádky by se měly zalamovat po nejvíce 72 znacích. Editor vim může zalamování automatizovat pomocí set tw=72.
git commit
Nechceme-li pracovat v editoru, máme možnost popis zadat rovnou přepínačem -m.
git commit -m "Kratky popis zmen"
push
Nahraje všechny lokálně vytvořené commity na vzdálený repozitář.
git push
Konflikty
Dojde-li k situaci, kdy dva uživatelé pracovali na stejném souboru a jeden nahrál změny do hlavního repozitáře, musí druhý uživatel před nahráním vlastních změn vyřešit potencionální konflikty.
Konflikt nastane v případě, že oba uživatelé upravili stejný řádek, nebo provedli podobné změny. Druhý uživatel musí tedy ručně (s pomocí gitu) zvolit, které řádky chce zachovat a které nahradit
Před vyřešením konfliktu je nutné lokální repozitář synchronizovat na poslední verzi.
Práce s vetvemi
Pro výběr větve, se kterou chceme pracovat, použijeme příkaz git checkout <branch>, ve kterém musíme zvolit správný název větve. Chceme-li větev vytvořit, můžeme příkaz rozšířit o přepínač -b, tj. git checkout -b <branch>. Mazání větví provádíme přepínačem -d.
Existující větve lze vypsat příkazem git branch -a. Aktivní větev je označena hvězdičkou.
Spojení větví se provádí příkazem git merge <branch>, který spojí specifikovanou větev s aktivní větví vybranou příkazem checkout.
Tagy
| Název | Programovací jazyk Python |
|---|---|
| Zodpovědná osoba | Dawid J. Kubis |
| Popis | V tomto předmětu se učí Python |
Python je rozšířený interpretovaný programovací jazyk, vhodný ke psaní skriptů, rychlých simulací a výpočtů.
Seznam materiálů
- Boolean výrazy
- Datové typy
- Dictionarary
- For - smyčka
- Funkce
- HTTP v Pythonu
- IF - Podmínka
- Importy
- Interpretace vs. kompilace
- Komentáře
- List comprehensions
- Operace
- Programovací jazyk Python
- Proměnné
- Python interpreter
- Range (rozsahy)
- Seznamy
- Ternární operátor
- While smyčka
- Základní funkce
| Název | Boolean výrazy |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Boolean výrazy
Boolean výrazy jsou výrazy které obsahují dvě možné hodnoty : True nebo False.
Operátory
Tyhle základní logické operátory rozlišujeme v pythonu :
<, > - menší než, větší než
>>> 2 < 3
True
>>> 2 > 3
False
==, != - rovnost, nerovnost
>>> 2 == 2
True
>>> 2 != 3
True
and, or - logické 'a' a 'nebo'
>>> True and True
True
>>> True and False # a obracene
False
>>> False and False
False
>>> True or True
True
>>> True or False # a obracene
True
>>> False or False
False
not - negace
>>> not True
False
>>> not False
True
Tagy
| Název | Datové typy |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Datové Typy
V programování existuje pojem datových typů, které specifikují jakého typu může být hodnota v proměnné.
Staticky a dynamicky typované jazyky
Staticky typované jazyky vyžadují specifikaci typu proměnné při její deklaraci (některé si typy doplňují při kompilaci a není potřeba je tam psát).
Dynamicky typované jazyky kontrolují typy při spouštění programu a tudíž se typy proměnných můžou měnit v průběhu práce.
Python je dynamicky typovaný jazyk :
>>> x = 3
>>> x
3
>>> x = 'foo'
>>> x
'foo'
Datové Typy
Teď si projedeme několik základních datových typů. Budu tady používat "funkci" type(), o které jsme se sice nezmíňovali ale hodí se na zjišťování datového typu proměnných.
int
Typ int (integer) je typ který popisuje nějaké celé číslo, kladné nebo záporné nebo nulové.
V Pythonu vypadá takhle :
>>> x = 2 # tohle je int
>>> x = -32 # tohle je taky int
>>> type(x)
<class 'int'>
float
Typ float je typ který popisuje nějaké číslo s destinnou čárkou, kladné nebo záporné nebo nulové (psáno jako 0.0).
>>> x = 2.3232 # tohle je float
>>> x = -32.4444 # tohle je taky float
>>> type(x)
<class 'float'>
str/String
Typ str (také String) je typ který popisuje nějaký textový řetězec. V Pythonu je do tohoto typu taky zahrnutý takzvaný typ char, který popisuje jeden znak.
Řeťezec by měl být obalen uvozovkami ("") nebo apostrofy ('') aby se dal odlišit od názvů proměnných.
>>> x = 'hello world' # str
>>> type(x)
<class 'str'>
>>>x = 'h' # taky str
>>> type(x)
<class 'str'>
bool
Typ bool (také boolean) je typ který má dvě možné hodnoty : True čili pravda nebo Falsečili nepravda.
Tento typ dokáže přímo pracovat z if-ama, jelikož je sám v sobě boolean výrazem.
>>> x = True
>>> x = False
>>> type(x)
<class 'bool'>
x = True
if x:
print('tohle se provede protoze x je pravda tudiz nemusime psat : "if x == True:'")
Tagy
| Název | Dictionarary |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Dict
dict je datový typ sloužící k ukládání hodnot pod určitými klíči. Jedná se určitým způsobem o něco jako pole, kde místo číselných indexů používáme libovolné neměnné objekty (čísla, stringy, tuply...)
Příklad:
>>> # Jedno z využití dictonary je snadná reprezentace složených dat
>>> mydict = {'jmeno': 'Lukáš', 'vek': 7893, 'poznamka': 'naposledy jsem to přestal počítat před 7893 lety'}
>>> mydict['vek']
7893
>>> # Za pomocí dictionary můžeme reprezentovat třeba i orientovaný graf.
>>> graph = {0: [2, 3], 1: [1, 0], 2: [3, 1]}
>>> graph[2] # Cesty z vrcholu číslo 2
[3, 1]
Tagy
python dictionary hashmap sbirka
| Název | For - smyčka |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
For
For slouží k procházení seznamů. Při definici píšeme název proměnné
(v příkladu dole je to i) do které se ukládají všechny hodnoty.
Například :
for i in range(10): # cisla od 0 do 100
print(i) # vypsani cisla
vypíše :
0
1
2
3
4
5
6
7
8
9
Tagy
| Název | Funkce |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Funkce
Funkce jsou jedna z nejpodstatnějších věcí o kterých se budeme bavit.
Funkce nám pomáhají neopakovat kód, jinými slovy díky funkcím můžeme znovupoužít kusy kódu.
Funkce slouží jako logické rozdělení toho jak má fungovat náš program.
def fungce():
print('tahle funkce nema zadny argumenty')
def funkce(argument, dalsi_argument):
print(argument)
print(dalsi_argument)
>>> fungce()
tahle funkce nema zadny argumenty
>>> funkce('hello', 'world')
hello
world
>>> funkce(1,2)
1
2
Input/Output
Vstup a výstup funkce zajištují argumenty a return hodnoty.
Argumenty píšeme do závorky za názvem funkce.
def funkce(argument, dalsi_argument):
# .. bla bla bla
# s argumenty pracujeme jako s promennymi
Return píšeme uvnitř funkce.
def funkce():
return 'ahoj' # tahle funkce vraci 'ahoj' po spusteni
# return ukonci praci funkce
>>> print(funkce())
ahoj
Pass
pass nám dovolí nechat nedopsanou funkci která nevyhodí error
při interpretaci. Má to svoji funkci když plánujeme co napíšeme a
tvoříme funkce ale není to podstatný si to pamatovat. Spíše se
jenom nedivte až to někde uvidíte.
def funkce():
pass
>>> funkce()
>>> # nic se nestalo lol
Tagy
| Název | IF - Podmínka |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
IF
If je blok který vyhodnocuje nějaký boolean výrazu (výrazu který vrací buď True nebo False)
a provadí určitý kód na základě toho, co dostane
Příklad
cislo = 12 # tady by mohl byt input() od uzivatele
if cislo % 2 == 0: # jeden blok (if - elif - else)
# if vzdy zacina blok, tudiz muze byt jen jeden v jednom bloku
print('cislo je sude') # toto se provede jelikoz 12 % 2 je 0
elif cislo % 3 == 0:
# elif-u tady muze byt 'nekonecne' mnoho
print('cislo je delitelne tremi') # toto se neprovede i presto ze 12 % 3 je 0
else:
# v jednom bloku muze byt else jenom jeden
print('cislo je liche') # toto by se provedlo kdyby se vsechno nad tim neprovedlo
Další Příklad
cislo = 12
if cislo % 2 == 0: # jeden blok
print('cislo je sude') # provede se
if cislo % 3 == 0: # dalsi blok (if - else)
print('cislo je delitelne tremi') # taky se provede
else:
print('cislo neni delitelne tremi') # neprovede se, patri k if-u nad tim
Tagy
| Název | Importy |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Importy
Importy nam slouzi k organizaci kodu nebo pouzivani kodu kterej napsal nekdo jinej.
Importovani vlastniho kodu
Rekneme ze mate takovouhle slozku:
.
├── lib.py
└── main.py
lib.py:
def hello(jmeno):
return "hello " + jmeno
print("tohle je modul lib.py") # pozor; tohle se spusti, hned vysvetlim
main.py:
import lib # ne `import lib.py`
print(lib.hello("world")) # ne `hello("world")` ale `lib.hello("world")`
Kdyz pak udelame python main.py a spustime tim program tak dostaneme:
tohle je modul lib.py # <- tohle dostaneme protoze pri importu se `lib.py` jakoby spusti, to ale nechceme
hello world # <- tohle je vystup z main.py, to co jsme chteli
Prave proto si davejte pozor co pisete do veci ktery pak importujete, idealne by neco mel delat jenom jeden soubor a zbytek by mel byt plny funkci (nic nedelat) abyste se nedostali k situaci kdy se vam neco posralo hledate to mezi vsema python souborama.
Importovani cizicho kodu
Cizi kod muzeme ziskat tim, ze si ho stahneme pomoci pipu z oficialnich repositari python moduluu.
Ukazeme si to na prikladu modulu requests, ktery nam dovoluje vyrizovat http requesty v pythonu.
Zacneme tim ze si ho stahneme:
pip install requests
nebo na nekterych kompech:
python -m pip install requests
Pak pockame az se stahne requests a muzeme pouzivat:
import requests
a = requests.get("https://raw.githubusercontent.com/Dawidkubis/python-gjk/master/8/importy.md")
print(a.text)
Schvalne zkuste co vam to vypise :D
Tagy
| Název | Interpretace vs. kompilace |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Interpretace vs. Kompilace
Source kód vs. strojový kód
Souce kód je kód napsaný v nějakém počítačovém jazyce, který sám o sobě nic neznamená.
Strojový kód jsou přímé instrukce pro počítač, tudíž soubory se strojovým kódem můžeme rovnou spustit. Jsou napsány v binárním kódu.
Kompilace vs. Interpretace
Kompilace je základní princip fungování počítačových jazyků. Idea je taková že vezmeme nějakej source kód a přeložíme ho na strojový kód. Programu který překládá se říká "compiler".
konkretne compiler preklada kod urovne vyssi (napriklad python) do urovne nizsi (napriklad pythoni bytecode)
- Karel Jílek
Tagy
| Název | Komentáře |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Komentáře
Komentář (anglicky comment) označuje sekci v kódu, která není určená pro Pythoní interpreter, ale pro programátora, který kód čte. Hodí se většinou pro přehlednost a taky když se podíváte na svůj kód po nějaké době tak aby se tomu dalo porozumět.
Ve větších projektech je komentování kódu vhodné, aby bylo snadnější se v kódu vyznat. V Pythonu se dělá znakem #.
Komentáře se v pythonu dělají následujícím způsobem:
print("Hello World") # Vsechno za znakem # je ignorovany
print("...")
Interpret jazyka Python prostě ignoruje vše, co se nachází po # na daném řádku
Je dobrým zvykem komentovat anglicky, protože je angličtina nejdůležitější jazyk v programování. My budeme komentovat česky bez znaků pro studijní účely ale vy nemusíte.
Tagy
| Název | List comprehensions |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
List Comprehensions
list comprehensions jsou super. Dovolujou zkratit kod uplne strasne moc.
Je to prakticky for kterej dovoluje filtrovat.
Tohle:
# chceme sebrat vsechna sudo cisla do 1000
n = []
for i in range(1000):
if i % 2 == 0:
n.append(i)
print(n)
Je ekvivalence:
n = [i for i in range(1000) if i % 2 == 0]
print(n)
coz muzeme cist jako: "n je seznam vsech cisel do 1000 kde zbytek z deleni dvemi je nula, tl;dr vsech sudych cisel"
Tagy
| Název | Operace |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Operace
+, - : sčítání, odčítání
>>> 2 + 3
5
>>> 2 - 3
-1
*, /, // : násobení, dělení
>>> 2 * 3
6
>>> 2 / 3 # vraci float
0.6666666666666666
>>> 2 // 3 # vraci int; deleni beze zbytku
0
** : umocňování
>>> 2 ** 3
8
>>> 2 ** (1/2) # muzeme umocnovat floatem; vychazi odmocnina ze dvou
1.4142135623730951
% : modulo
Modulo je operace která vrací zbytek z dělení, hodí se na zjišťování dělitelnosti čísel (viz. sude_nebo_liche.py).
>>> 17 % 2
1
>>> 17 % 9
8
Tagy
| Název | Proměnné |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Proměnná
Proměnná (anglicky variable) je základ ukládání hodnot v programu. Narozdíl od matematiky je proměnná v programování (v jazyce Python) přepisovatelná (můžeme jít měnit).
Do proměnné se zapisuje za pomocí =.
Příklad:
>>> x = 10
>>> x = x + 1
>>> x
11
Je vhodné pojmenovávat proměnné krátkými názvy (proměnná text_od_uzivatele_k_parsingu je hrůza) ale s dostatečným významem (nechceme mít v kódu celou abecedu protože se v tom nikdo nevyzná).
Proměnné píšeme s malým počátečním písmenem, a bez mezer (_ na místě mezery). Python to sice nepožaduje, ale dělá se to tak, aby jiní lidé nebyli z vašeho kódu zmatení a nenadávali vám.
Tagy
| Název | Python interpreter |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Python Interpreter
Python interpreter je program jež nám umožňuje spustit skript který jsme si napsali. Pokud je v $PATH (což by měl být) tak ho můžeme volat z příkazového řádku (takhle to vypadá u mě) :
$ python
Python 3.7.4 (default, Jul 16 2019, 07:12:58)
[GCC 9.1.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Když takhle zavoláme Python bez argumentů, tak se interpreter spustí v tzv. interaktivním módu. Vocaď můžeme Python používat jako kalkulačku, například :
>>> 2 * 3
6
>>> 2 + 3
5
>>> x = 2 * 3
>>> x * 70
420
Python nám automaticky vyprintuje hodnoty všech výrazů, což je specialita interaktivnícho módu.
Když chceme spustit nějaký soubor s python kódem, musíme přidat cestu k souboru jako argument.
$ python <nazev_skriptu>.py
Všechny python skripy by měly končit koncovkou .py.
Toto bude fungovat jenom pokud jste ve stejné složce jako je <nazev_skriptu>.py, jinak budete muset specifikovat relativní nebo absolutní cestu, případně přejít do složky se skriptem pomocí příkazu cd. Více o cestách a shellových příkazech najdete zde (windowsáci si budou muset v mysli nahradit ls za dir)
Tagy
| Název | Range (rozsahy) |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Range
Range popisuje seznam celých čísel v nějakém intervalu.
range(10) jsou čísla 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
range(5, 10) jsou čísla 5, 6, 7, 8, 9
Pozor, když chcete s range pracovat jako se seznamem čísel,
čili provádět na seznamu operace a ne jenom procházet pomocí for tak
si ten range uložte jako
x = list(range(10))
Tagy
| Název | HTTP v Pythonu |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Http
Http je způsob komunikace ktery se pouziva na siti.
Http posila data, vetsinou ve formatu html, kterej nespis znate ale neplette si ty pojmy.
Http zacina headerem kterej popisuje:
- jestli je to pozadavek nebo odpoved (request & response)
- pokud je to odpoved tak jestli doslo k nejaky chybe
- pokud je to pozadavek tak co se vlastne po tom serveru chce
Http metody
- GET - chceme ziskat obsach, vetsinou html, ze serveru. Neposilame zadny data
- POST - chceme neco postnout na server, posilame data v nejakym formatu (vetsinou
json) Je jich vic, ale to tady nebudu rozebirat. Pokud vas to zajima tak si to vygooglete.
Requests
Requests nam dovoli pracovat s tema http metodama a posilat http pozadavky (requesty - proto requests).
GET
import requests # viz. importy.md
response = requests.get("https://google.com") # posilame GET na google
# tohle se bezne deje kdyz nacitame tu stranku v prohlizeci
print(response.text) # html ktery jsme dostali zpatky, prohlizec tyto data zpracuje
# aby to nejak hezky vypadalo
# responese ma jeste mnoho veci ktery jsme mohli tahat
# treba:
#response.status_code
# atd, ale to nebudu rozebirat, proste se s tim da delat hromada veci
POST
To tady nebudu resit, ted se mi to nechce psat
Tagy
| Název | Seznamy |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Seznamy
Seznamy nám dovolují ukládat hodnoty v seznamu (lol) a pracovat s nima. Datové typy v seznamech se sice můžou lišit ale je lepší aby všechny byly stejné. Jednotlivé prvky v seznamech jsou označeny tzv. indexem, což je číslo které popisuje kolikátý prvek to je.
>>> x = [1, 2, 3]
>>> x[0] # prvek v `x` s indexem 0
1
>>> x[1]
2
>>> x[2]
3
operace na seznamech
>>> x = [1,2,3]
>>> len(x) # delka x
3
>>> x.append(4) # prida prvek na konec seznamu
>>> x
[1, 2, 3, 4]
>>> x.pop() # odebere prvek z konce seznamu
4
>>> x
[1, 2, 3]
Tagy
| Název | Ternární operátor |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Tenarni operator
Unarni operatory jsou operatory ktery berou 1 vstup. Napriklad not je unarni operator.
Binarni operatory jsou operatory ktery berou 2 vstupy. Napriklad + je binarni operator.
Tenarni operator je operator ktery bere 3 vstupy. Ten je v pythonu tedy jenom jeden vypada takto:
n = 2 # nejaky cislo
print("sudy" if n % 2 == 0 else "lichy") # vypise `sudy` protoze n je sudy
coz je ekvivalence:
n = 2
if n % 2 == 0:
print("sudy")
else:
print("lichy")
Tagy
| Název | Programovací jazyk Python |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Třídy a Objekty
Třídy v programování popisují nějaký "typ" určité hodnoty.
Například hodnota 1 je typu int, hodnota 'ahoj' je typu str - typy jsou třídy a hodnoty objekty.
Třídy popisují jen obecné vlastnosti a činnosti (funkce, u tříd se jim říká metody).
Objekty jsou instance třídy, které mají nějaké konktrétní hodnoty.
Takhle vypadá definice třídy v pythonu:
class Clovek: # tridy se nazyvaji s velkym pocatecnim pismenem
def __init__(self, age, height):
self.age = age # self.age patri objektu, age je argument metody
self.height = height
Metoda __init__ je tzv. konstruktor, čili je volána vždy když tvoříme objekt.
self je proměnná do které se automaticky přiřadí objekt.
Takle vypadá konstrukce objektu třídy člověk:
x = Clovek(18, 180)
Je dobré si všimnout, že při konstrukci jsme dali metodě __init__ jen dva argumenty, i když v definici bere tři.
To je proto, že objekt se automaticky přiřadí k proměnné self (nebo jakékoli proměnné která bude na začátku).
Protože __init__ je konstruktor, tak k self se přiřadí prázdný objekt, kterému potom dáváme nějaké vlastnosti.
Je to lechce podobný proces jako při práci se slovníky:
def init(age, height)
x = dict()
x["age"] = age
x["height"] = height
return x
Až na to, že k datům objektu přistupujeme pomocí tečky (x.age místo x["age"]).
Tagy
| Název | While smyčka |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
While
Bere booleanovský výraz jako argument.
Loopuje dokud je výraz True.
while True:
print('tohle bezi donekonecna')
i = 0
while i < 10
print(i) # tohle se provede 10krat
i += 1
Tagy
| Název | Základní funkce |
|---|---|
| Autor | Neznámý |
| Naposledy upravil | Lukáš Hozda |
| Poslední změna | 2021-01-24 22:53:14 +0100 |
| Předmět | Programovací jazyk Python |
Základní funkce
V naší první hodině jsme probrali několik funkcí. Funkce je kus kódu, který můžeme volat na vícero místech (to si ale do detailu probereme později).
Syntax volání
Nyní potřebujete znát hlavně základní syntax volání funkcí. Funkce může dostávat nějaké argumenty, což jsou jakési vstupy, které funkce zpracovává. Různé funkce mají různý počet argumentů. Je to asi nějak takhle:
jmeno_funkce(argument1, argument2, ...)
Funkce může vracet nějaký výstup, který si můžeme například uložit do proměnné. Třeba takhle:
ahoj = nejaka_funkce()
Pár funkcí do základní výbavy
My jsme probrali několik funkcí.
Nejzákladnější je funkce print. Ta bere neomezený počet argumentů, které spojí mezerou a vypíše do konzole.
Příklad
print("Hello World")
jmeno = "Dawid"
print("Ahoj", jmeno) # Vypíše Ahoj Dawid
input
Dále jsme probrali funkci input. Ta bere maximálně jeden argument.
Funguje tak, že čeká, dokud uživatel nezadá nějaký vstup a zmáčkne enter a vrátí vstup, který uživatel zadal.
Když dostane argument, tak jej vypíše uživateli před místo, kam zadává vstup.
jmeno = input("Zadej prosím své jméno.")
int
Jako poslední jsme probrali funkci int (což je spíše datový typ, ale my budeme předstírat, že je to funkce). Ta nám převede nějaký string (zadaný jako argument) na celé číslo, pokud je to možné. Jestliže to možné není, tak hodí chybu (později se naučíme, jak se s takovouhle chybou vyrovnat).
Příklad:
ahoj = "1234" # Všimněte si, že ahoj je string (typ str)
ahoj_cislo = int(ahoj) # ahoj_cislo je nyní celé číslo
Tagy
Vyučující
Božena Patáková Dawid J. Kubis Emil Miler Julie Jará Karel Jurečka Lukáš Hozda Milan Špaček Richard Šašek Viktorie Koláčková Zbyněk Stříbrný
Božena Patáková
- email: patakova@gjk.cz
- username: patakova
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Dawid J. Kubis
- email: xkubda01@gjk.cz
- username: dawidkubis
Bio
Předměty
Materiály
Emil Miler
- email: miler@gjk.cz
- username: nixi
Bio
Tento profil doopravdy nepatří Emilovi, ale slouží jako demonstrace toho, když se na materiálech podílí více autorů
Předměty
Materiály
Julie Jará
- email: jara@gjk.cz
- username: jara
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Karel Jurečka
- email: jurecka@gjk.cz
- username: jurecka
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Lukáš Hozda
- email: me@magnusi.tech
- username: luciusmagn
Bio
další informace -> https://magnusi.tech/
Předměty
Materiály
Milan Špaček
- email: spacek@gjk.cz
- username: spacek
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Richard Šašek
- email: sasek@gjk.cz
- username: sasek
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Viktorie Koláčková
- email: kolackova@gjk.cz
- username: kolackova
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Zbyněk Stříbrný
- email: stribrny@gjk.cz
- username: stribrny
Bio
falešný profil pro zaplnění databáze učitelů
Předměty
Materiály
Tagy
algoritmy aritmetika bool c class comment crypto dictionary for fp funkce git hashmap http if imperativni import interpretace kodovani kompilace list loop networking objekt oop operator os pamet paradigma pravo promenne python range sbirka security shell ternarni typy unicode unix variable vcs vector while
algoritmy
aritmetika
bool
c
class
comment
crypto
dictionary
for
fp
funkce
git
hashmap
http
if
imperativni
import
interpretace
kodovani
kompilace
list
loop
networking
objekt
oop
operator
os
pamet
paradigma
pravo
promenne
python
- Boolean výrazy
- Datové typy
- Dictionarary
- For - smyčka
- Funkce
- HTTP v Pythonu
- IF - Podmínka
- Importy
- Interpretace vs. kompilace
- Komentáře
- List comprehensions
- Operace
- Programovací jazyk Python
- Proměnné
- Python interpreter
- Range (rozsahy)
- Seznamy
- Ternární operátor
- While smyčka
- Základní funkce
range
sbirka
security
shell
ternarni
typy
unicode
unix
- Bezpečnost
- Huffmanovo kódování
- Imperativní programování
- Kódování znaků
- Minimalizace
- Paměti
- Programovací jazyk C
- Prvo v IT
- Reprezentace čísel v paměti
- Shell
- Složitosti algoritmu
- Sítě
- Unix
- Verzovací systém git
- Verzovací systémy